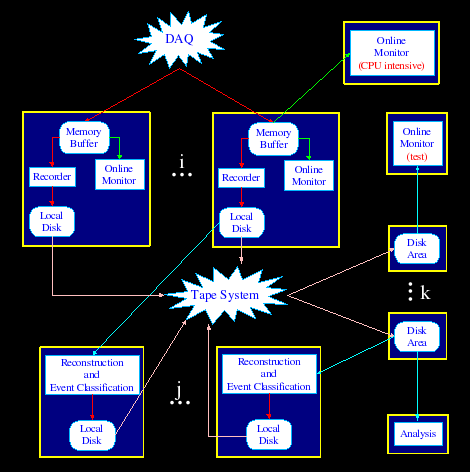
The KLOE Data Handling system (DH) is responsible for the moving around KLOE events. Most of the time this means locating a file registered in the KLOE relational database, moving it to a user accessible disk area and then read out the events, but the DH system is also capable of accessing any YBOS file or even a memory buffer, both locally and remotely.
The DH system is composed of the following pieces:
A very important role is also played by the KLOE relational database, especially the bookkeeping and system catalog sections.
To achieve its goals, KLOE is acquiring huge amounts of data; the estimated needs are around 200G events for a total storage size of 1 PB. To efficiently manage all these data, a multi-layer scheme is used.
Most of the data in the KLOE environment are produced as a result of the readout of the FEE after the trigger system has identified a possibly interesting event. These data are collected together, formatted and written to a raw file on an online disk pool. Some events, like BhaBha events, are easy to identify after they have been formatted and they are also very interesting for monitoring and calibration purposes. For these reasons they get duplicated during the data acquisition process and written to separate raw files that make another source of data. Whichever the source, after a raw file reaches a set maximum size, it is closed and marked read-only, ready-to-be-analyzed and ready-to-be-archived.
Another source of data are simulated or MC events. They are produced by MC generators, that simulate physics dynamics and create events that contain the same information it would be read-out by the FEE (plus some MC specific data). These events are written to mcraw files on a temporary disk area. When the desired amount of events has been created, the file is closed and marked read-only and ready-to-be-analyzed.
Once a raw file is declared ready-to-be-analyzed, it is processed by an offline reconstruction process. Each event contained in the input file is reconstructed and assigned to one or more classes or streams. For each stream that was marked as to be saved, the event is written in a dedicated datarec file (once for every stream) on an offline disk pool. Once all the events from the input file has been processed, all the related datarec files are closed and marked read-only and ready-to-be-archived. A similar process takes place also when a mcraw file is declared ready-to-be-analyzed, but streaming is normally not performed; that is, all the events are written in a mc file. Moreover, when the mc file is closed, the mcraw file is deleted from its disk area, since all its data are contained in the new mc file.
When a file is declared ready-to-be-archived, it is processed by the archiver process that copies it to the tape library. Once archived, the file can be deleted from its disk pool to make space for new files.
When a raw, datarec or mc file is declared read-only, it can be read-out by an analysis process. However, the disk pool where the file was written may not be (and normally is not) visible by the target machine and moreover the file could have been already canceled from the disk pool, so a copy of it is created on a recall disk pool by the data handling system. Once the copy is created (or an existing copy located), the requesting process can access it. The copy is guaranteed to stay on that disk pool as long as at least one process is accessing it, but can be deleted from the disk pool shortly afterward to make space for a copy of another file.
All these activities are obviously unfeasible to be carried on by the final user.
See also the following figure:
KID, or KLOE Integrated Dataflow, is the main interface to the data handling system. Its major advantage it the ease of use; it allows a user to access one or more sources of KLOE events using a simple URI, such as:
dbraw:run_nr=22000 and stream_code='ALL'
fastdatarec:run_nr=22222 and version=13 and stream_code='rad'
spydaq:ALL
The library itself is very modular; the core services are just URI parsers, that redirect calls to plug-ins. The standard library comes complete with several plug-ins, the most used being:
ybos – read a file from a local disk
spydaq – read events from the DAQ buffers
db... - a set of plug-ins that select a list of files using an SQL query and access the files with the help of the recall system (without further user involvement); the actual plug-ins are:
dbraw – DAQ files, using logger.raw_data table
dbdatarec – reconstructed files and DSTs, using logger.datarec_data table
dbmc – Monte Carlo files, using logger.mc_data table
fast... - like db... plug-ins, but skip files that need to be recalled from tape; the actual plug-ins are:
fastraw – DAQ files, using logger.raw_data table
fastdatarec – reconstructed files and DSTs, using logger.datarec_data table
fastmc – Monte Carlo files, using logger.mc_data table
but users can add their own ones, just following simple rules.
For more details, see the dedicated page.
Since copies of the KLOE files can be located in several places and not all of them are accessible by the users, the recall system is normally contacted to obtain a location for the needed files (i.e. a recall disk area). If the file is already on a recall disk area, just the area index will be returned, else the recall system will take care of making a copy on the least used recall area, using the fastest available source.
The recall daemon is the heart of the data handling system. All the request regarding file movement, except the archiving ones, are managed by this process.
A process needing some files sends to the daemon the list of those, together with a list of possible recall areas. If a file is already on one of these areas, it just notifies the client where to find it. Else, it makes a copy of the file, using one of the file management daemons, on one of the specified areas and then notifies the client.
The main API for the recall system is a C library; it implements the whole communication protocol to the recall daemon. On top of it, a tcl command has also been implemented.
For more details on both the daemon and the APIs, see the dedicated page.
KID, and occasionally the APIs of the recall system, are very useful when writing applications that must access the KLOE data, but some command line interface is also needed, especially for non-programmers.
Currently three command line tools are available:
kls - list the location of files
recall - copy a list of files to a specific recall area
kcp - copy a list of files to a user area
The syntax is similar for all of the above commands. The user is asked to select the file type (raw, datarec or mc) and give a where part for an SQL query on the logger.xxx_data table (raw_data, datarec_data or mc_data). Moreover, the search can be restricted only to files that are already on a disk area.
The complete syntax is:
kls [options] type query
where: options - optional flags, see below type - raw, datarec or mc query - where part of an SQL query based on logger.type_data options: -l - long format -b - brief format, show only the best one -d - disk only, show only files that are on disk
recall type [options] recall_area query
where: type - raw, datarec or mc recall_area - location to put the files query - where part of an SQL query based on logger.type_data options: -b - batch mode, print out only the filenames -d - disk only, recall only files that are on at least a disk
kcp [options] type query outdir
where: type - raw, datarec or mc query - where part of an SQL query based on logger.type_data outdir - output directory options: -f - force, overwrite files -n - new, do not overwrite files -i - interactive, ask for every file if it is to be copied -b - batch, write out only file names (skip duplicate files by default) -d - disk only, copy only files that are on disk
The output of kls is a set of lines, where each line contains a filename and a list of locations where the file resides. Files can be located:
only on tape, in which case the on tape label is printed
on one or more disk locations; in this case all the disk locations will be printed, with the following syntax
online - the file is located on the DAQ disk pool (/data/farm)
offline - the file is located on the offline (/datarec)
recalled (followed by a list recall areas) - the file is available on the listed recall areas
nor on disk nor on tape, so the lost label is printed
An example of use:
kls datarec "stream_code='bgg' and version=16 and run_nr=22653"
Found 24 files:
bgg022653N_ALL_f05_1_1_1_16.000 0.2Mb offline recalled: {f0a 14}
bgg022653N_ALL_f05_1_1_1_16.001 0.2Mb offline recalled: {f0a 14}
bgg022653N_ALL_f05_1_1_1_16.002 0.2Mb offline recalled: {f0a 14}, {f0b 14}
bgg022653N_ALL_f05_1_1_1_16.003 0.1Mb on tape
bgg022653N_ALL_f05_1_1_1_16.004 0.1Mb offline
bgg022653N_ALL_f05_1_1_1_16.005 0.2Mb on tape
bgg022653N_ALL_f05_1_1_1_16.006 0.2Mb on tape
bgg022653N_ALL_f05_1_1_1_16.007 0.2Mb offline
bgg022653N_ALL_f06_1_1_1_16.000 0.2Mb on tape
bgg022653N_ALL_f06_1_1_1_16.001 0.2Mb offline
bgg022653N_ALL_f06_1_1_1_16.002 0.2Mb offline recalled: {f0a 15}
bgg022653N_ALL_f06_1_1_1_16.003 0.1Mb offline
bgg022653N_ALL_f06_1_1_1_16.004 0.1Mb offline recalled: {f0a 14}, {f0a 15}
bgg022653N_ALL_f06_1_1_1_16.005 0.1Mb offline
bgg022653N_ALL_f06_1_1_1_16.006 0.2Mb on tape
bgg022653N_ALL_f06_1_1_1_16.007 0.2Mb on tape
bgg022653N_ALL_f07_1_1_1_16.000 0.2Mb offline
bgg022653N_ALL_f07_1_1_1_16.001 0.2Mb offline
bgg022653N_ALL_f07_1_1_1_16.002 0.2Mb on tape
bgg022653N_ALL_f07_1_1_1_16.003 0.1Mb offline
bgg022653N_ALL_f07_1_1_1_16.004 0.1Mb offline
bgg022653N_ALL_f07_1_1_1_16.005 0.1Mb on tape
bgg022653N_ALL_f07_1_1_1_16.006 0.2Mb on tape
bgg022653N_ALL_f07_1_1_1_16.007 0.2Mb on tapeLimiting the output only to files on disk:
kls -d datarec "stream_code='bgg' and version=16 and run_nr=22653"
Found 14 files:
bgg022653N_ALL_f05_1_1_1_16.000 0.2Mb offline recalled: {f0a 14}
bgg022653N_ALL_f05_1_1_1_16.001 0.2Mb offline recalled: {f0a 14}
bgg022653N_ALL_f05_1_1_1_16.002 0.2Mb offline recalled: {f0a 14}, {f0b 14}
bgg022653N_ALL_f05_1_1_1_16.004 0.1Mb offline
bgg022653N_ALL_f05_1_1_1_16.007 0.2Mb offline
bgg022653N_ALL_f06_1_1_1_16.001 0.2Mb offline
bgg022653N_ALL_f06_1_1_1_16.002 0.2Mb offline recalled: {f0a 15}
bgg022653N_ALL_f06_1_1_1_16.003 0.1Mb offline
bgg022653N_ALL_f06_1_1_1_16.004 0.1Mb offline recalled: {f0a 14}, {f0a 15}
bgg022653N_ALL_f06_1_1_1_16.005 0.1Mb offline
bgg022653N_ALL_f07_1_1_1_16.000 0.2Mb offline
bgg022653N_ALL_f07_1_1_1_16.001 0.2Mb offline
bgg022653N_ALL_f07_1_1_1_16.003 0.1Mb offline
bgg022653N_ALL_f07_1_1_1_16.004 0.1Mb offlineSee also the KID page for more examples, especially the dbraw, dbfastraw, dbdatarec, dbfastdatarec, dbmc and dbfastmc protocols, and the dedicated pages.
The archiving daemon is in charge of archiving the newly produced files, i.e. of making a copy of those files on disk. This process is asynchronous of all the other processes; its task is to make sure all the files are archived, while keeping the number of tape mounts as low as possible and also enough space on the DAQ and offline disk pool at all times.
For more details, see the dedicated page.
Three types of file management processes are currently in place:
archADSMd - the interface to the
tape storage system
It can give information about the files
archived in the tape library and copy files to and from it.
filekeeper - the manager of recall
disk areas
Creates the files on the local recall disk areas,
deleting not-recently-used files when space is needed.
spacekeeper - the manager of the
DAQ and offline disk areas
Deletes allready-archived files, when
occupancy of the local DAQ or offline disk area is getting critical.
Each of them has its own tasks and does not interact directly with the others. See their dedicated pages for more details.
Send comment to Igor Sfiligoi.