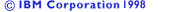Transcoding Classes
This file contains the following subjects:
Transcoding is the process of converting
text data between two coded character sets using a mapping rules.
The goal of the Open Class libraries is for
all text to be encoded in Unicode and manipulated according to
the Unicode character encoding standard. Any text you import from
or export to a system that uses a different character encoding
scheme must be transcoded so that the text can be manipulated
directly on the target system.
The Open Class transcoding classes support
conversion of character data to and from Unicode and a wide
variety of other encoding sets and encoding schemes, including
ASCII and other ISO standards, to enable you to import and export
text data between Open Class applications and other environments.
The Open Class transcoders use the UniChar datatype
to represent Unicode characters in IText
objects and the char datatype to represent
non-Unicode characters in IString
objects.
The transcoding classes also provide
mechanisms for handling characters that don't have obvious
mappings between Unicode and another character set. These
mechanisms handle both line-breaking characters, which differ
between platforms, and exception characters. Exception characters
are characters that can often be transcoded but do not have a
one-to-one mapping. These may include ligature characters,
foreign characters, or composed characters.
The transcoding classes are:
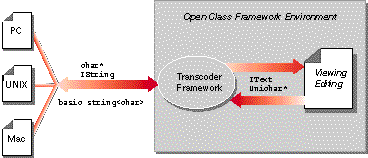
ITranscoder provides the abstract protocol
for all transcoders supported by the Open Class system. You
create a transcoder by specifying a character set to
ITranscoder::createTranscoder, which returns an instance of the
ITranscoder subclass supporting that character set.
This figure shows some of the available
transcoders:
ITranscoder is currently the only public
transcoder class. You access all concrete subclasses through the
ITranscoder interfaces.
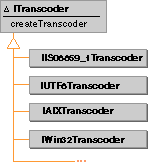
ITranscoder provides both a simple,
high-level interface, which converts between IText and IString
instances, and a low-level interface, based on the ANSI C++
Standard codecvt interface, which takes pointers to char
and UniChar arrays. The high-level
functions take two parameters, a char-based IString
object and a UniChar-based IText object, and convert
either to or from Unicode data.
The low-level pointer-based functions let
you manipulate char and UniChar strings
directly. Some of the low-level functions
are identical to the interfaces provided by the ANSI C++ standard
library codecvt class. They allow you to specify
exact ranges of text to transcode and to provide error-recovery
mechanisms.
This figure shows the ITranscoder interface:
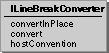
ILineBreakConverter is a simple class that
you use to ensure that line breaking characters are transcoded
correctly between Unicode and the target character set. You can
use ILineBreakConverter to postprocess strings just converted
into Unicode, or preprocess strings before converting them into char
data.
This figure shows the ILineBreakConverter
interface:
ILineBreakConverter uses the enum
ELineBreakConvention to describe different line-breaking
conventions. Currently the following conventions are defined:
ILineBreakConverter uses the following rules
to convert between various host line-breaking conventions and
Unicode:
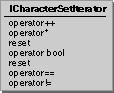
Use ICharacterSetIterator to iterate through
the list of character encoding sets for which transcoders are
available on the current system. ICharacterSetIterator returns
IText objects that contain the names of supported character sets.
This figure shows the interface for
ICharacterSetIterator:
The ITranscoder transcoding functions
provide special handling for both line-break and exception
characters.
The class ILineBreakConverter provides for
conversion between the Unicode paragraph-separator character
(U+2029 or UGeneralPunctuation::kParagraphSeparator) and the
appropriate line-break character for a given character set or
host. You can use this class to postprocess transcoded strings
after conversion into Unicode or to preprocess strings before
conversion into char-based formats.
ITranscoder also lets you control how
exception characters are handled. Exception characters are
characters that do not have a single-character equivalent or that
do not exist in the target character set. For example, Greek
characters may be used in some environments where they are not
part of the native character set, and ligature characters, which
by definition combine two characters, are often mapped to a
sequence of their individual components. The following table
shows some typical cases:
To specify how you want exception characters
to be handled, call the ITranscoder::setUnmappedBehavior
function. You can specify a substitution character, in either
Unicode or the target character set, or you can specify that the
transcoder either skip exception characters or stop the
transcoding operation when it reaches one.
By default, transcoders substitute
UGeneralFunction::kReplacementCharacter (U+FFFD) for Unicode
characters with no mapping, and the ASCII substitution character
(UASCII::kSubstitute, or 0x1A) for char characters
with no mapping.
The transcoders let you specify how you want
exception characters to be handled. Exception characters are
characters for which there are no one-to-one mappings between
Unicode and the target character set. Use the EUnmappedBehavior
enum to specify one of the following:
If you don't specify behavior for exception
character handling, the transcoder uses
EUnmappedBehavior::kUseSub as the default. The substitute
characters that are used are:
You can set the char substitute
character to another character with the ITranscoder function
setCharSubstitute. Whether to display these characters as glyphs
or as text strings is left to the host operating system.
When you create a transcoder for a specific
character set, you can specify how close the mapping proximity
must be between Unicode and the target character set. Use the
EMappingProximity enum to specify one of the following:
If you don't specify a mapping proximity,
the transcoder uses EMappingProximity::kSupersetMapping as the
default.
Transcoder Names
Instantiating a Transcoder
Iterating Through Available
Transcoders
Converting Text
from Unicode to Character Format
Converting Text
from Character Format to Unicode
Processing Line-breaking
Characters
Using ANSI C++
Compatible Transcoding Functions
Verifying Transcoding Results