Capitolo 327. PostgreSQL: accesso attraverso WWW-SQL
WWW-SQL (1) è un programma CGI in grado di creare pagine HTML a partire dalle informazioni ottenute da una base di dati PostgreSQL o MySQL. In questo capitolo si vuole vedere in particolare l'interazione rispetto alle basi di dati di PostgreSQL. In ogni caso, per poter leggere questo capitolo, occorre sapere cosa sia un programma CGI e come interagisce con un servente HTTP, come spiegato a partire dal capitolo 162. La scelta di collocare qui queste informazioni, è dovuta al fatto che si tratta di un argomento legato alla programmazione SQL; inoltre, WWW-SQL è praticamente un interprete di un linguaggio specifico, che gli permette di definire le richieste alla base di dati e di generare il risultato finale desiderato.
È molto probabile che la propria distribuzione GNU/Linux abbia organizzato due pacchetti distinti, in base all'uso che se ne intende fare, per l'abbinamento con PostgreSQL, oppure con MySQL. In questo modo, il nome del programma CGI a cui si deve fare riferimento può cambiare leggermente, anche da una distribuzione all'altra. Qui si fa riferimento al nome www-pgsql per quello che riguarda l'uso con PostgreSQL.
327.1 Principio di funzionamento
Ammesso che il pacchetto organizzato dalla propria distribuzione sia stato realizzato nel modo corretto, l'eseguibile www-pgsql dovrebbe trovarsi nella directory più adatta per i programmi CGI, ovvero quella a cui si accede normalmente con l'URI http://localhost/cgi-bin/. In tal caso, per accedere a questo programma, basta avviare il proprio navigatore preferito e puntare sull'indirizzo http://localhost/cgi-bin/www-pgsql. Ma non basta, dal momento che il programma in questione ha bisogno di interpretare un file HTML speciale dal quale restituisce poi un risultato. Per capire come funziona la cosa, prima ancora di avere affrontato lo studio del linguaggio specifico di WWW-SQL, si può provare con un file HTML normale: si supponga di avere a disposizione il file http://localhost/index.html; per fare in modo che WWW-SQL lo analizzi, basta indicare l'URI http://localhost/cgi-bin/www-pgsql/index.html. Il risultato è identico all'originale, ma per arrivare a questo si passa attraverso l'elaborazione del programma CGI, dimostrando così il suo funzionamento.
Volendo, se il proprio programma servente HTTP è Apache, è possibile rendere la cosa più elegante attraverso una configurazione opportuna del file srm.conf (si veda a questo proposito il capitolo 160 su Apache). Per esempio si potrebbe fare in modo che i file che terminano con l'estensione .pgsql vengano elaborati automaticamente attraverso il programma CGI in questione:
Action www-pgsql /cgi-bin/www-pgsql AddHandler www-pgsql pgsql
Tuttavia, occorre considerare che alcune installazioni di Apache sono state predisposte in modo da impedire l'utilizzazione dell'istruzione Action. Se dopo le modifiche di questo file, il servizio di Apache non si riavvia, ciò potrebbe essere un sintomo di questo problema.
327.2 Preparazione delle basi di dati e accesso
Perché il programma CGI possa accedere alle basi di dati di PostgreSQL, occorre ricordare di predisporre gli utenti e i permessi necessari all'interno della gestione delle basi di dati stesse. Di solito, si prevede la possibilità di accesso per l'utente nobody, dal momento che il servente viene avviato solitamente con i privilegi di questo utente e, di conseguenza, il programma CGI eredita la stessa personalità.(2) Vale la pena di ricordare che per PostgreSQL occorre aggiungere l'utente nobody nel modo seguente:
postgres$ createuser nobody
Quindi occorre intervenire nelle basi di dati regolando i permessi attraverso i comandi GRANT e REVOKE, tenendo conto che a questo proposito si può consultare quanto già spiegato nel capitolo 324. Per fare un esempio, volendo concedere l'accesso in lettura alla tabella Indirizzi, della base di dati anagrafe, all'utente nobody, si potrebbe agire come si vede di seguito:
postgres$ psql anagrafe[Invio]
anagrafe=> GRANT SELECT ON Indirizzi TO nobody;[Invio]
Tuttavia, occorre tenere in considerazione il fatto che non tutte le distribuzioni GNU/Linux sono organizzate in modo che i privilegi di funzionamento del programma servente del servizio HTTP siano pari a quelli dell'utente nobody. Per esempio, nel caso della distribuzione GNU/Linux Debian, viene usato l'utente apposito www-data: questo nome particolare, non può essere inserito negli utenti di PostgreSQL, a causa del fatto che contiene un trattino (-), per cui, occorre agire in modo differente, ma questo verrà descritto in seguito, in occasione della descrizione dell'istruzione <! SQL CONNECT >.
327.3 Linguaggio di WWW-SQL
WWW-SQL interpreta un file HTML alla ricerca di istruzioni secondo il formato schematizzato di seguito:
<!ĀSQLĀcomandoĀ[argomento...]Ā>
Come si vede, queste istruzioni assomigliano a dei commenti per l'HTML, ma anche se non lo sono realmente, di solito i navigatori ignorano dei marcatori di questo tipo. Tuttavia, questa si può considerare solo come una misura di sicurezza, dal momento che questi file non dovrebbero essere raggiunti direttamente, ma solo attraverso l'intermediazione di WWW-SQL.
Le istruzioni di WWW-SQL rappresentano un linguaggio di programmazione, semplice, ma efficace per lo scopo che ci si prefigge. Si osservi che il «comando» è una parola chiave che rappresenta il tipo di azione che si intende svolgere; inoltre, gli argomenti possono essere presenti o meno, in funzione del comando. Gli argomenti di un comando possono essere racchiusi tra apici doppi ("..."): all'interno di queste stringhe si possono indicare delle variabili da espandere e si possono usare anche delle sequenze di escape per rappresentare simboli speciali che altrimenti avrebbero un altro significato.
Per iniziare subito con un esempio che faccia capire la logica di funzionamento di WWW-SQL, si osservi il «programma» seguente, rappresentato dal file variabili.pgsql:
<HTML>
<HEAD>
<TITLE>Esempio sul funzionamento delle variabili con WWW-SQL</TITLE>
</HEAD>
<BODY>
<H1>Esempio sul funzionamento delle variabili con WWW-SQL</H1>
<P><! SQL PRINT "var = $var" ></P>
<p><FORM ACTION="variabili.pgsql" METHOD="GET">
<INPUT NAME="var">
<INPUT TYPE="submit">
</form></p>
</BODY>
L'unica istruzione per WWW-SQL è <!SQL PRINT...>, con la quale si vuole ottenere la visualizzazione di una stringa tra apici doppi. Si osservi che $var è il riferimento alla variabile var, che viene espanso, come parte della valutazione della stringa.
Come si può intuire leggendo l'esempio, i campi definiti attraverso i modelli (gli elementi FORM), si traducono in variabili per WWW-SQL.
Per verificare il funzionamento di questo programma, supponendo di avere collocato il file variabili.pgsql nella directory iniziale dei documenti HTML offerti dal servente HTTP, basta puntare il navigatore sull'indirizzo http://localhost/cgi-bin/www-pgsql/variabili.pgsql (sempre ammettendo che l'indirizzo http://localhost/cgi-bin/www-pgsql corrisponda all'avvio del programma CGI che costituisce in pratica WWW-SQL).
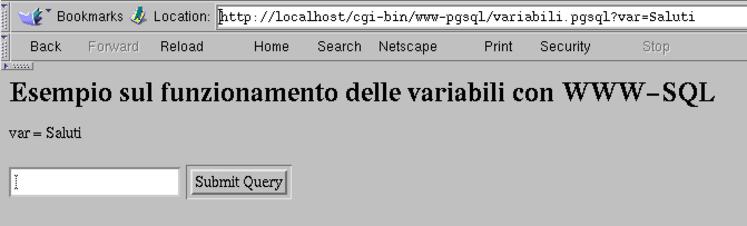
Quello che si ottiene dovrebbe essere un modulo HTML molto semplice, dove si può inserire un testo. Inviando il modulo compilato, dovrebbe essere restituito lo stesso modulo, con la stringa iniziale aggiornata, dove viene mostrato che è stato recepito il dato inserito (nella figura 327.1 si vede che era stata inviata la stringa «Saluti».
|
Figura 327.1. Risultato dell'interpretazione del file
|
327.3.1 Espressioni
Si distinguono due tipi di espressioni che si possono valutare all'interno delle istruzioni di WWW-SQL: quelle che si applicano ai valori numerici e quelle che si applicano alle stringhe. Le tabelle 327.1 e 327.2 elencano gli operatori che possono essere utilizzati a questo proposito. Si osservi in particolare l'operatore :, che permette di fare un confronto tra una stringa e un'espressione regolare.
Tabella 327.1. Elenco degli operatori utilizzabili con operandi numerici.
| Operatore e operandi | Descrizione |
| +op | Non ha alcun effetto. |
| -op | Inverte il segno dell'operando. |
| op1 + op2 | Somma i due operandi. |
| op1 - op2 | Sottrae dal primo il secondo operando. |
| op1 * op2 | Moltiplica i due operandi. |
| op1 / op2 | Divide il primo operando per il secondo. |
| op1 % op2 | Modulo -- il resto della divisione tra il primo e il secondo operando. |
| op1 ^ op2 | Eleva il primo operando alla potenza del secondo. |
| op1 == op2 | Vero se gli operandi sono uguali. |
| op1 = op2 | Vero se gli operandi sono uguali (sinonimo di ==). |
| op1 != op2 | Vero se gli operandi sono differenti. |
| op1 > op2 | Vero se il primo operando è maggiore del secondo. |
| op1 < op2 | Vero se il primo operando è minore del secondo. |
| op1 >= op2 | Vero se il primo operando è maggiore o uguale al secondo. |
| op1 <= op2 | Vero se il primo operando è minore o uguale al secondo. |
| ! op | Negazione logica. |
| op1 && op2 | AND logico. |
| op1 & op2 | AND logico (sinonimo di &&). |
| op1 || op2 | OR logico. |
| op1 | op2 | OR logico (sinonimo di ||). |
Tabella 327.2. Elenco degli operatori utilizzabili con operandi di tipo stringa.
All'interno delle stringhe è prevista l'espansione di variabili e sono anche riconosciute alcune sequenze di escape (tabella 327.3). Le variabili in questione vanno intese come parte del linguaggio di WWW-SQL; alcune di queste sono la ripetizione di variabili di ambiente corrispondenti, altre sono variabili interne del programma (come elencato nella tabella 327.4), altre ancora possono essere definite all'interno del «programma» stesso, o meglio ancora, attraverso dei moduli, come è stato mostrato nell'esempio iniziale. Le variabili vengono riconosciute in quanto scritte secondo lo schema seguente:
prefissonome_della_variabile
Il prefisso è un simbolo a scelta tra: $, @, ?, #. In pratica, $var, @var, ?var, e #var, sono riferimenti identici alla stessa variabile var. Per questo motivo, se si vogliono usare i simboli corrispondenti a questi prefissi in modo letterale, occorre usare una sequenza di escape.
Tabella 327.3. Sequenze di escape utilizzabili all'interno delle stringhe.
| Escape | Significato |
| \\ | \ |
| \" | " |
| \n | <LF> |
| \t | <HT> (tabulazione) |
| \$ | $ |
| \@ | @ |
| \# | # |
| \? | ? |
| \~ | ~ |
Tabella 327.4. Variabili interne di WWW-SQL.
Per prendere confidenza con le variabili interne di WWW-SQL, si può realizzare lo script seguente (interne.pgsql), che con l'istruzione <!SQL DUMPVARS> le elenca tutte. La figura 327.2 mostra il risultato che si potrebbe ottenere.
<HTML>
<HEAD>
<title>Visualizzazione delle variabili interne</title>
</HEAD>
<BODY>
<H1>Visualizzazione delle variabili interne</H1>
<! SQL DUMPVARS >
</BODY>
|
Figura 327.2. Esempio del contenuto delle variabili interne attraverso l'istruzione <!SQL DUMPVARS>.
|
327.3.2 Strutture di controllo
Attraverso le istruzioni di WWW-SQL, si possono realizzare le strutture di controllo che sono comuni nei linguaggi di programmazione. È prevista la struttura condizionale e il ciclo iterativo.
<!ĀSQLĀIFĀespressioneĀ>
ĀĀĀĀ...
[<!ĀSQLĀELSIFĀespressioneĀ>]
ĀĀĀĀ...
[<!ĀSQLĀELSEĀ>]
ĀĀĀĀ...
<!ĀSQLĀENDIFĀ>
La struttura condizionale che si vede nello schema, permette di delimitare uno spazio da filtrare in base all'esito delle espressioni condizionali coinvolte. Per esempio,
<! SQL IF $NUM_ROWS == 10 >
<P>Il numero delle righe è uguale a 10.</P>
<! SQL ELSE >
<P>Il numero delle righe non corrisponde a
quanto previsto.</P>
<! SQL ENDIF >
in questo modo si condiziona la visualizzazione di una frase in base al fatto che la variabile NUM_ROWS contenga o meno il valore 10.
|
È importante osservare che l'espressione usata come condizione di controllo potrebbe restituire un risultato numerico e non logico. In tal caso, lo zero corrisponde a Falso, mentre qualunque altro valore corrisponde a Vero. |
<!ĀSQLĀWHILEĀespressioneĀ>
ĀĀĀĀ...
<!ĀSQLĀDONEĀ>
La struttura iterativa che si vede nello schema, permette di delimitare uno spazio da interpretare ripetitivamente, finché l'espressione condizionale introduttiva continua a restituire il valore Vero (o un valore numerico diverso da zero).
<! SQL SET contatore 10 >
<! SQL WHILE $contatore > 0 >
<P>Il contatore ha raggiunto il livello <! SQL PRINT "$contatore" >.</P>
<! SQL SETEXPR contatore $contatore - 1 >
<! SQL DONE >
L'esempio mostra l'inizializzazione di una variabile, denominata contatore, al valore iniziale 10; quindi inizia un ciclo iterativo che si arresta quando tale variabile raggiunge lo zero. A ogni ciclo, viene visualizzato il contenuto della variabile, che subito dopo viene ridotto di un'unità.(3)
Nell'ambito di un'iterazione, possono essere usate delle istruzioni per interrompere il ciclo in corso o per interrompere tutta l'iterazione:
<!ĀSQLĀCONTINUEĀ>
<!ĀSQLĀBREAKĀ>
La prima della due istruzioni interrompe il ciclo attuale, facendo riprendere immediatamente l'iterazione, mentre il secondo interrompe l'iterazione del tutto.
Esiste anche un altro tipo di iterazione, il cui scopo è la scansione delle righe ottenute dall'interrogazione di una base di dati:
<!ĀSQLĀPRINT_LOOPĀriferimento_all'interrogazioneĀ>
ĀĀĀĀ...
<!ĀSQLĀDONEĀ>
Anche all'interno di questa struttura si possono usare le istruzioni <!SQL CONTINUE> e <!SQL BREAK>.
327.4 Istruzioni
Le istruzioni «normali» di WWW-SQL, ovvero quelle che non servono a descrivere delle strutture di controllo, sono descritte in questa sezione e in quelle seguenti. In particolare si può notare che WWW-SQL offre delle istruzioni per la lettura semplificata dell'esito di un'interrogazione SQL e altre per la lettura dettagliata, fino ad arrivare a distinguere riga per riga e campo per campo.
Segue un elenco di istruzioni di tipo vario, mentre nelle sezioni seguenti vengono raccolte altre istruzioni più specifiche.
-
Emissione di una stringa con espansione di variabili:
<!ĀSQLĀPRINTĀstringaĀ>L'istruzione <!SQL PRINT ...> permette di emettere una stringa. Dal momento che un file HTML non ha bisogno di accorgimenti particolari per mostrare una stringa costante, è evidente che il senso di questa istruzione sta nella possibilità di indicare delle variabili da espandere, come nell'esempio seguente:
<P>Il contatore ha raggiunto il livello <! SQL PRINT "$contatore" >.</P>
-
Risultato di un'espressione:
<!ĀSQLĀEVALĀespressioneĀ>L'istruzione <!SQL EVAL ...> è simile a <!SQL PRINT ...>, con la differenza che l'argomento non è più una stringa, ma un'espressione differente, il cui risultato viene emesso alla fine.
-
Impostazione di una variabile:
<!ĀSQLĀSETĀnome_variabileĀvalore_da_assegnareĀ>L'istruzione <!SQL SET ...> permette di definire e inizializzare una variabile. L'esempio seguente definisce la variabile contatore, inizializzandola a zero:
<! SQL SET contatore 0 >
-
Impostazione di una variabile attraverso un'espressione:
<!ĀSQLĀSETEXPRĀnome_variabileĀespressioneĀ>L'istruzione <!SQL SETEXPR ...> permette di definire e inizializzare una variabile; in particolare, il valore che si assegna può essere il risultato della valutazione di un'espressione. L'esempio seguente definisce la variabile contatore, inizializzandola con il risultato dell'espressione $contatore - 1. In pratica viene decrementato il contenuto della variabile contatore:
<! SQL SETEXPR contatore $contatore - 1 >
-
Definizione di un valore predefinito per il contenuto di una variabile:
<!ĀSQLĀSETDEFAULTĀnome_variabileĀvalore_da_assegnareĀ>L'istruzione <!SQL SETDEFAULT ...> permette di stabilire un valore predefinito per una variabile; a differenza di <!SQL SET ...> la variabile non viene modificata se esiste già e ha un valore. L'esempio seguente definisce la variabile contatore, solo se necessario, inizializzandola con il valore 10:
<! SQL SETDEFAULT contatore 10 >
-
Elenco variabili:
<!ĀSQLĀDUMPVARSĀ>L'istruzione <!SQL DUMPVARS> emette l'elenco delle variabili esistenti, assieme al valore che contengono. Può essere usato per scopo diagnostico, quando si cerca di capire cosa succede realmente.
327.4.1 Apertura e chiusura di una connessione, e accesso a una base di dati
L'interrogazione di una base di dati deve essere preceduta dalla connessione a un servente DBMS e dalla selezione di una base di dati; inoltre, al termine delle interrogazioni, si passa normalmente alla chiusura di una connessione, in pratica secondo lo schema seguente:
<!ĀSQLĀCONNECTĀ...Ā>
<!ĀSQLĀDATABASEĀnome_della_base_di_datiĀ>
...
...
<!ĀSQLĀCLOSEĀ>
In breve: <!SQL CONNECT ...> serve a iniziare una connessione con un servente per l'accesso a una base di dati; <!SQL DATABASE ...> serve a indicare la base di dati specifica presso il servente; <!SQL CLOSE> chiude la connessione.
-
<!ĀSQLĀCONNECTĀ[hostĀ[utenteĀ[parola_d'ordine]]]Ā>L'istruzione <!SQL CONNECT ...> permette di iniziare una connessione con un DBMS. Dipende dal DBMS stesso se è possibile accedere senza alcun sistema di autenticazione. In generale, se non si indica il nodo a cui accedere, si intende
localhost; inoltre, se non si indica l'utente, si fa riferimento al numero UID con il quale funziona il programma servente del servizio HTTP (che a sua volta avvia il programma CGI). Se si utilizza una distribuzione GNU/Linux Debian, occorre considerare che il servente HTTP funziona con i privilegi dell'utente www-data e che si tratta di un nome impossibile per PostgreSQL. In questo caso, occorre indicare dettagliatamente tutti gli argomenti, con l'eccezione della parola d'ordine che può essere omessa se PostgreSQL è stato configurato in modo da non richiederla. L'esempio che segue richiede di connettersi al servente DBMS PostgreSQL che opera nello stesso elaboratore locale, utilizzando l'identità dell'utente nobody e senza specificare alcuna parola d'ordine:<! SQL CONNECT localhost nobody >
-
Selezione di una base di dati specifica:
<!ĀSQLĀDATABASEĀnome_base_di_datiĀ>L'istruzione <!SQL DATABASE ...> permette di aprire una base di dati specifica; per la precisione, utilizzando PostgreSQL, l'accesso al servente avviene solo dopo che è stata specificata la base di dati.
-
Chiusura di una connessione:
<!ĀSQLĀCLOSEĀ>La chiusura di una connessione (e quindi anche di una base di dati aperta), si ottiene con l'istruzione <!SQL CLOSE>.
Prima di passare alla descrizione delle istruzioni che permettono l'interrogazione del contenuto di una base di dati, viene mostrato un esempio che si limita a elencare la tabella Indirizzi della base di dati anagrafe:
<HTML>
<HEAD>
<TITLE>Esempio di interrogazione</TITLE>
</HEAD>
<BODY>
<H1>Esempio di interrogazione</H1>
<! SQL CONNECT localhost nobody >
<! SQL DATABASE anagrafe >
<! SQL QUERY "SELECT * FROM Indirizzi" RICHIESTA_1 >
<! SQL QTABLE RICHIESTA_1 >
<! SQL FREE RICHIESTA_1 >
<! SQL CLOSE >
</BODY>
327.4.2 Istruzioni di interrogazione normali
L'interrogazione di una base di dati avviene attraverso la definizione di un riferimento, che si apre e si chiude come se fosse un flusso di file nei linguaggi di programmazione comuni. Per aprire questo riferimento si inizia con l'invio di un'interrogazione SQL; successivamente si potrà leggere l'esito dell'interrogazione attraverso il riferimento che è stato aperto; infine si passa alla chiusura del riferimento:
<!ĀSQLĀQUERYĀstringa_di_interrogazione_sqlĀriferimentoĀ>
...
...
<!ĀSQLĀFREEĀriferimentoĀ>
-
Apertura di un'interrogazione:
<!ĀSQLĀQUERYĀstringa_di_interrogazione_sqlĀriferimentoĀ>L'istruzione <!SQL QUERY ...> definisce una stringa di interrogazione da inviare al servente DBMS. A questa interrogazione viene abbinato un riferimento costituito da un nome, che in seguito deve essere usato per leggere l'esito dell'interrogazione. Nell'esempio che appare nella sezione precedente, si vedeva l'istruzione seguente con la quale si selezionano tutte le righe della tabella Indirizzi, abbinando questo risultato al nome RICHIESTA_1:
<! SQL QUERY "SELECT * FROM Indirizzi" RICHIESTA_1 >
-
Tabella rapida:
<!ĀSQLĀQTABLEĀriferimentoĀ[borders]Ā>L'istruzione <!SQL QTABLE ...> consente di rappresentare rapidamente il risultato di un'interrogazione attraverso una tabella HTML. In particolare, utilizzando la parola chiave borders, la tabella che si genera avrà i bordi delle caselle visibili. L'esempio seguente mostra in che modo visualizzare rapidamente il risultato dell'interrogazione abbinata al nome RICHIESTA_1:
<! SQL QTABLE RICHIESTA_1 >
-
Elenco rapido:
<!ĀSQLĀQLONGFORMĀriferimentoĀ>L'istruzione <!SQL QLONGFORM ...> si utilizza in modo simile a <!SQL QTABLE ...>, per rappresentare il risultato di un'interrogazione attraverso un elenco dettagliato, senza una tabella HTML.
-
Chiusura del riferimento all'interrogazione:
<!ĀSQLĀFREEĀriferimentoĀ>Come è stato mostrato all'inizio, l'istruzione <!SQL FREE ...> serve a chiudere il riferimento a un'interrogazione.
-
Realizzazione di un elenco di voci da selezionare:
<!ĀSQLĀQSELECTĀriferimentoĀvariabile_modulo_htmlĀ>Con l'istruzione <!SQL QSELECT ...> si ottiene un elenco di voci di un modulo di selezione. In generale, la cosa corrisponde a:
<SELECTĀNAME="variabile_modulo_html">
<!ĀSQLĀPRINT_ROWSĀriferimentoĀ"<OPTIONĀNAME=\"@riferimento.0\">riferimento.1">
</SELECT>L'istruzione <!SQL PRINT_ROWS ...> è descritta nella prossima sezione.
327.4.3 Istruzioni per la selezione dettagliata di righe e campi
È possibile selezionare in maniera più precisa le righe e i campi di ciò che si ottiene da un'interrogazione SQL. Attraverso l'istruzione <!SQL FETCH riferimento> si preleva la riga attuale dall'interrogazione a cui si fa riferimento. Questo prelievo permette di fare riferimento agli elementi della riga attraverso una notazione particolare:
@riferimento.n
In pratica, è come se fosse l'espansione di una variabile, con la differenza che si indica il nome di un riferimento a un'interrogazione aperta, aggiungendo un'estensione numerica, separata da un punto, dove lo zero corrisponde al primo campo e n-1 corrisponde al campo n-esimo.
-
Modifica della riga attuale all'interno del risultato di un'interrogazione:
<!ĀSQLĀSEEKĀriferimentoĀn_rigaĀ>L'istruzione <!SQL SEEK ...> permette di modificare la riga attuale all'interno di un'interrogazione. Per indicare il numero della riga, occorre tenere presente che lo zero corrisponde alla prima. L'esempio seguente fa in modo che la riga attuale diventi la seconda del riferimento RICHIESTA_1:
<! SQL SEEK RICHIESTA_1 1 >
-
Prelievo della riga attuale di un certo riferimento:
<!ĀSQLĀFETCHĀriferimentoĀ>L'istruzione <!SQL FETCH ...> permette di rendere disponibile il contenuto della riga attuale di un certo riferimento. L'esempio seguente preleva il contenuto della riga attuale del riferimento RICHIESTA_1; quindi mostra il primo e il secondo campo di questa riga, che si presume corrispondano al cognome e al nome di una persona:
<! SQL FETCH RICHIESTA_1 > <P>Cognome: <! SQL PRINT "@RICHIESTA_1.0" ></P> <P>Nome: <! SQL PRINT "@RICHIESTA_1.1" ></P>
-
Emissione di una stringa per ogni riga:
<!ĀSQLĀPRINT_ROWSĀriferimentoĀstringaĀ>L'istruzione <!SQL PRINT_ROWS ...> è una sorta di istruzione <!SQL PRINT ...> ripetuta per tutte le righe di un'interrogazione, a partire da quella corrente. L'esempio seguente mostra la visualizzazione dei primi due campi di tutte le righe di un'interrogazione, a cui si fa riferimento con il nome Q:
<! SQL SEEK Q 0 > <! SQL PRINT_ROWS Q "<P>Cognome: @Q.0</P>\n<P>Nome: @Q.1</P>\n" >
L'esempio seguente mostra la realizzazione di un modulo per la selezione di un articolo, attraverso l'invio del codice corrispondente. A questo proposito, si suppone che la prima colonna del risultato dell'interrogazione a cui si fa riferimento con il nome ELENCO, corrisponda al codice dell'articolo, mentre la seconda corrisponda a una sua descrizione:
<p><FORM ACTION=ordine.pgsql> <SELECT NAME="codice"> <! SQL PRINT_ROWS ELENCO "<OPTION NAME=\"@ELENCO.0\">@ELENCO.1" > </SELECT> <INPUT TYPE="submit"> </FORM></p>
Dal momento che si fa riferimento alle prime due colonne, la stessa cosa avrebbe potuto essere realizzata con l'istruzione <!SQL QSELECT ...>, nel modo seguente:
<p><FORM ACTION=ordine.pgsql> <! SQL QSELECT ELENCO codice > <INPUT TYPE="submit"> </FORM></p>
327.5 Riferimenti
-
James Henstridge, WWW-SQL
daniele @ swlibero.org2) Naturalmente, lo stesso discorso può valere per un utente fittizio diverso, realizzato appositamente per il controllo della gestione del servizio HTTP.
3) Se l'istruzione <!SQL WHILE...> non viene riconosciuta, significa che non è disponibile la scansione iterativa.